PwC. 2024
ZERO DATA HUNT: FAST & CONSISTENT PERFORMANCE REVIEWS
Kelly, a Development Leader, dreaded review season — a desk buried in sticky notes, 57 tabs open, and constant pings. For each review, days were lost hunting data and formatting feedback, leaving little energy for meaningful feedback.
Across the company, DLs echoed her pain: ‘I end up with 50–60 tabs open trying to find one or two things.' What should be a chance to celebrate growth has become a compliance exercise.
Impact: 8-10 direct reports/ DL
The results
Cut review time for one direct report from 3 hours to less than an hour, saving over 10,000 DLs hours - equivalent to $800,000 in productivity recaptured every review cycle by using AI to surface the most relevant insights.
The breakthrough
We began by mapping the 'Annual review ecosystem' to uncover where Kelly was losing the most time. Three patterns emerged:
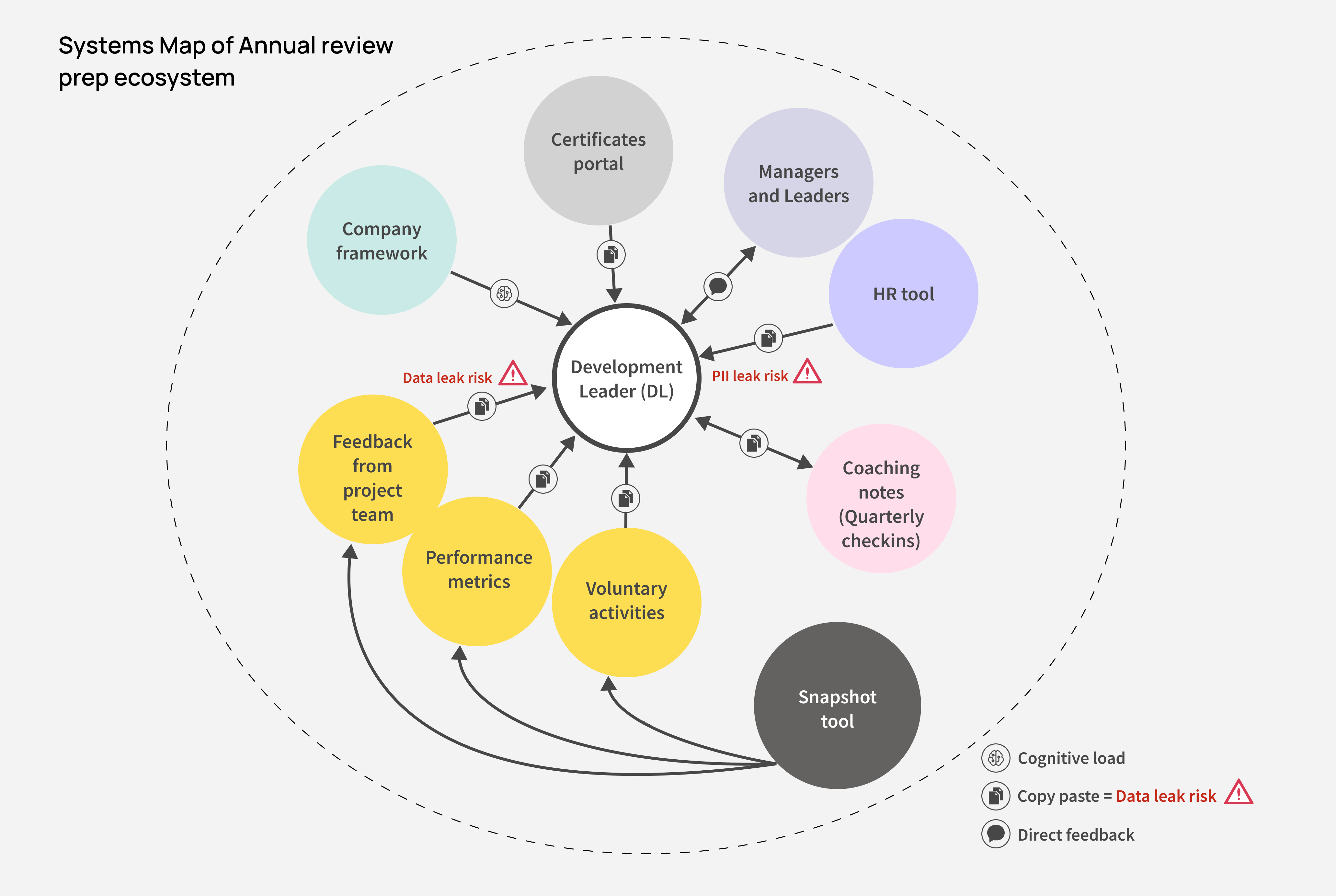
Centralized evidence, delivered through AI-generated summaries and key metrics will eliminate the heavy data hunt.
The time some DLs spend on getting direct feedback or formatting the final version are out of scope and will be integrated only if post‑launch evidence shows they’re still needed.

One DL said, ‘If I could see at a glance who’s on track and who’s not, I’d have 50% of my job done.’
The MVP
We identified the upstream issue: lack of regular monitoring of direct reports makes review season heavy and slow for DLs. To prove ROI and build trust in the data feeds, we kept the MVP small—performance summary —then we’ll expand to a monitoring dashboard using the same data cards.
How might we integrate performance evidence into the review workflow to cut review time to one-third while maintaining trust and data security?
UX strategy
DESIGN EVOLUTION
During our research to identify key metrics, a revelation emerged: DLs don’t focus solely on key metrics; instead, they need the status of all metrics—especially those ‘Not met’ by the reportee. This insight shaped our information architecture.
.jpg)
2. UI layout
We chose a split view—review form on one side, evidence on the other—to support long summaries and keep context visible, avoiding drawers that block the background and accordions that bury content.
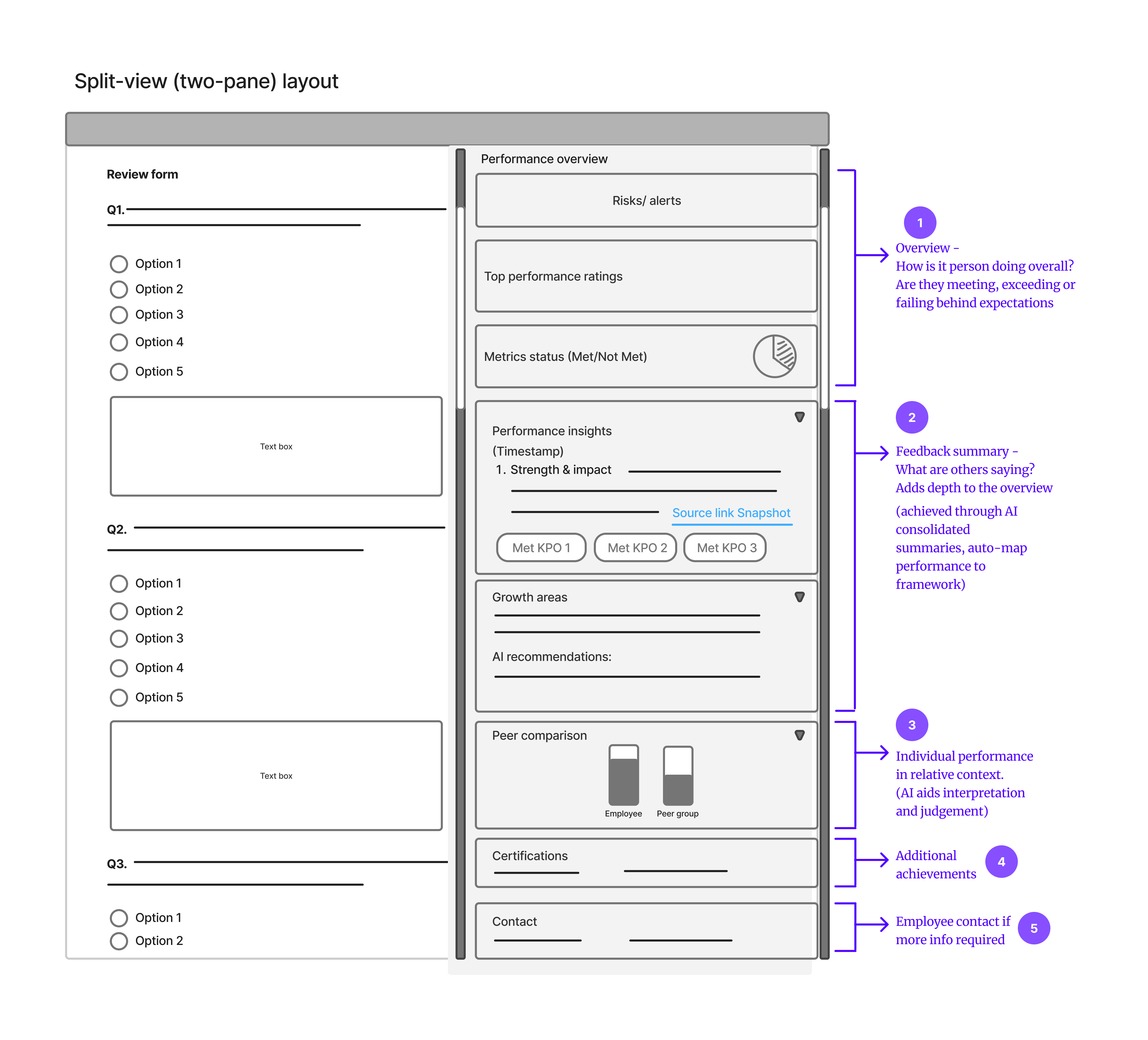
3. How did AI function as an enabler?
"All the evidence is right there — I can focus on judgment, not the search." said one DL during testing.
4. User research
We conducted 10 unmoderated sessions across North America, the UK, and India. This was a task-based prototype study in which users were asked to complete feedback for a performance review while we observed their process.
Key findings
Solving for scrolling fatigue
I replaced the long accordion with a content teaser card. This card surfaces the first bullet and hints users to click 'View details' to navigate to a dedicated detail page with the full list.

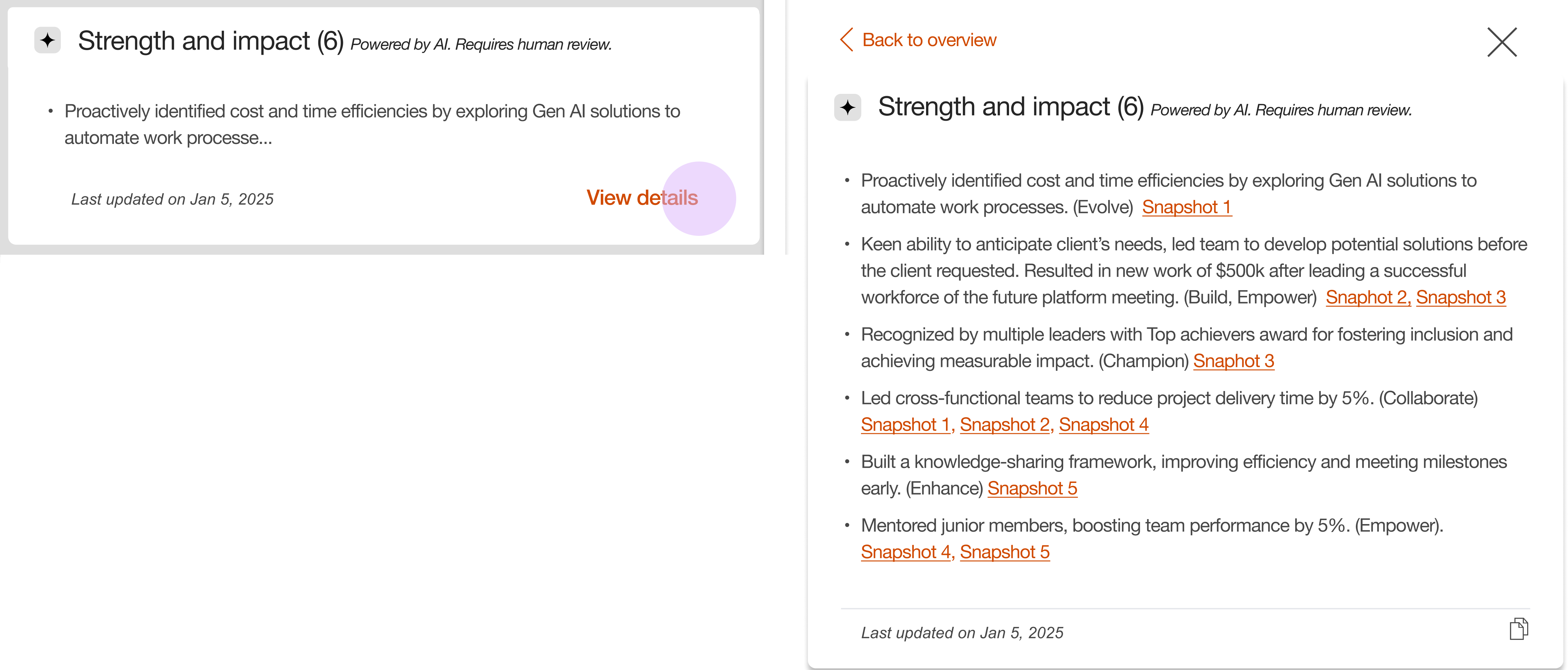
Improving trust in the data
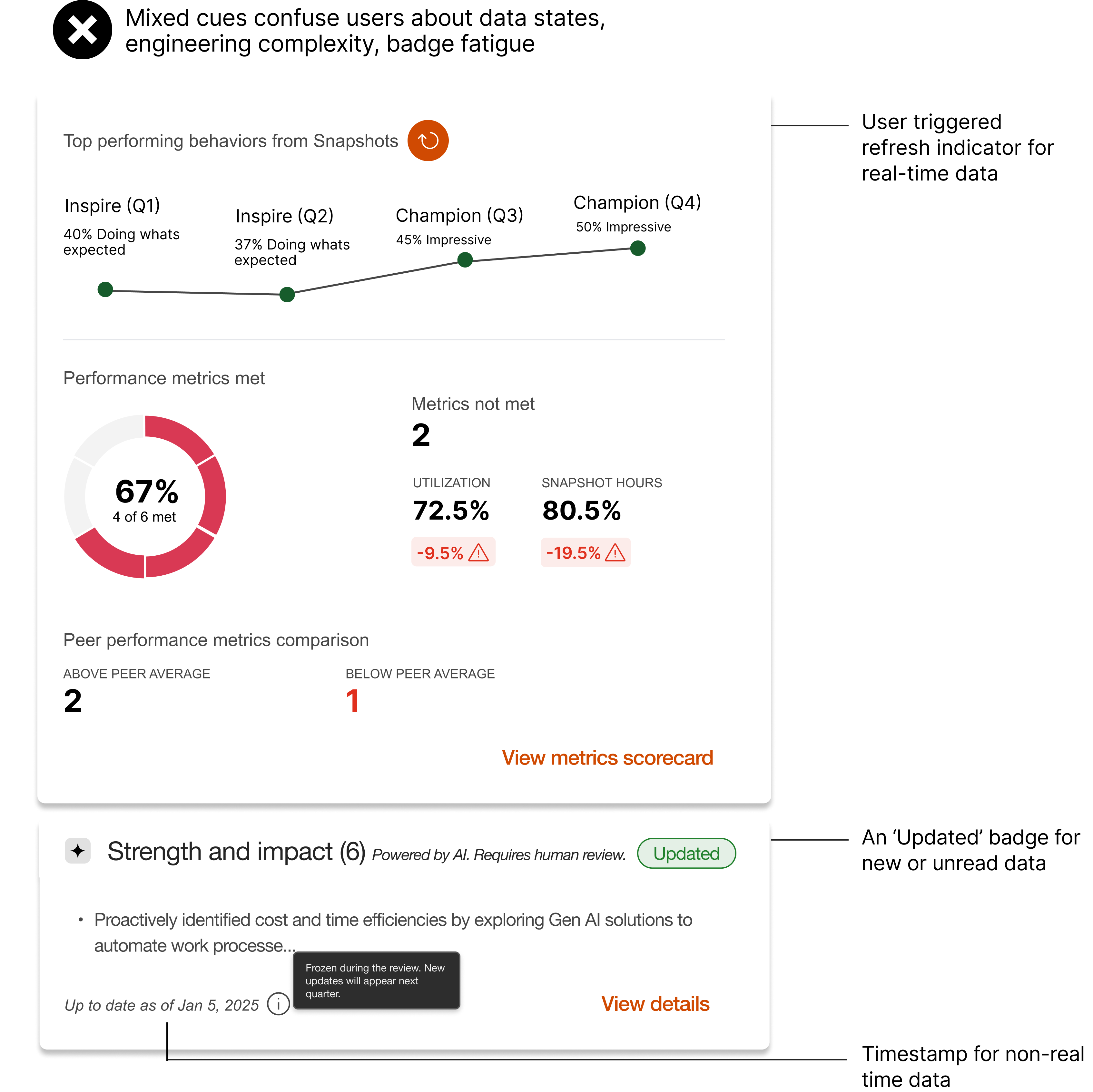
Inconsistent timestamps across sections create uncertainty about data recency which undermines trust and fairness.
What we considered?
Label both real time and non real-time sections using icons, badges, colors or tooltips for clear distinction.
Why we didn't - High noise, badge fatigue and still easy to misread under time pressure.
Decision
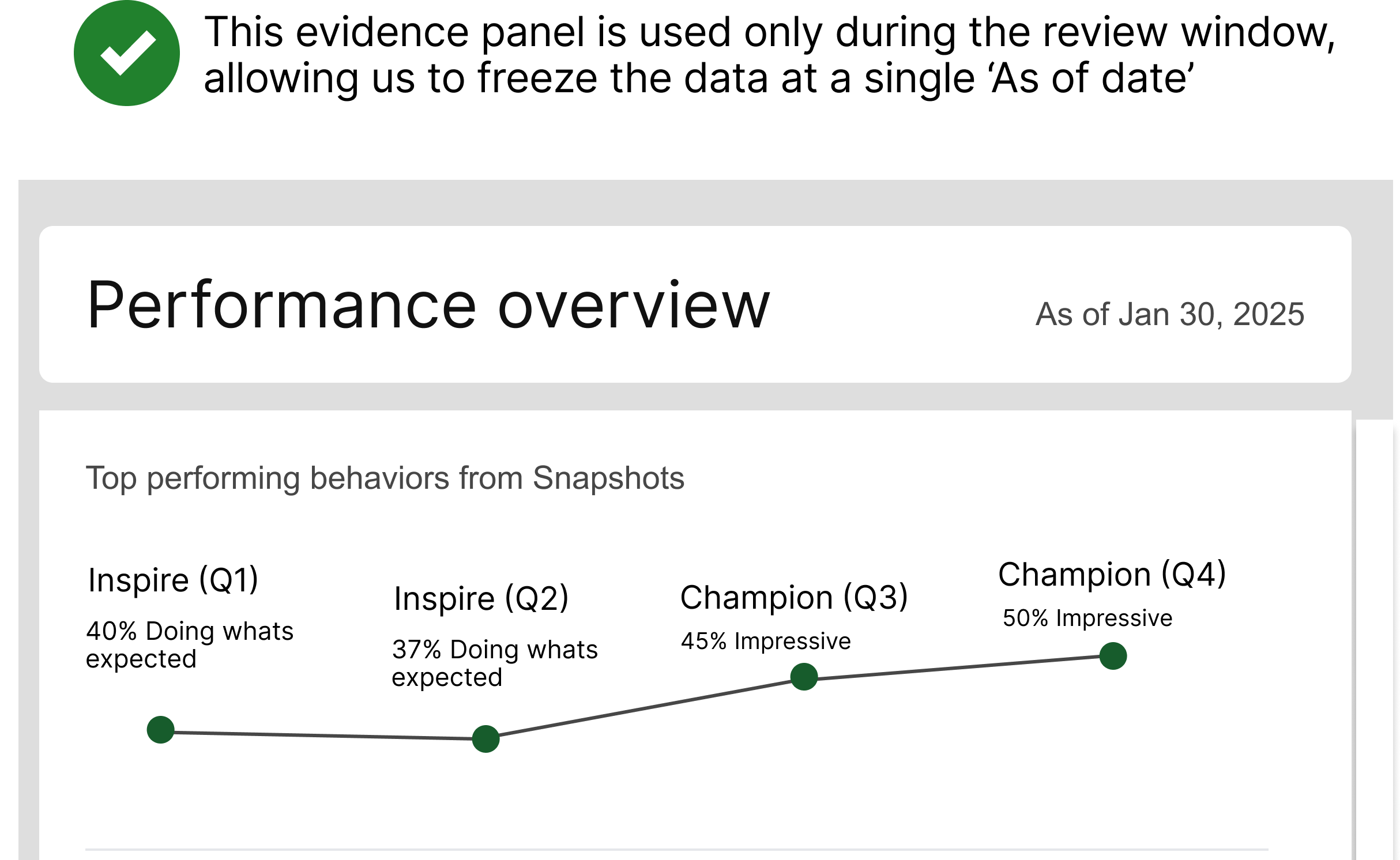
This insight made us look at our current process. We adopted a single cutoff date for the evidence panel to eliminate ambiguity.
How did we show it in UI?
Panel-level banner with a 'As of date'.
Peer switching
I added a left panel listing reportees so DLs can switch between them without leaving the form - speeding feedback comparisons and reducing memory load (recognition over recall).
"I need a simple way to indicate the quality of the AI summary. Right now I can't tell the sytem what it got wrong or right." - One DL said.
Participants want the ability to rate the AI summary.
To measure AI summary quality, we decided against a "rate this summary" button due to its cost, risk, volume and complexity. Instead, we now rely on user-initiated support tickets and implicit analytics. This approach simplifies the interface and provides us with labeled training data to continuously improve the model.
The overall success hinges on minimizing AI errors and ensuring data security.
THE PAYOFF
“It used to take hours to compile data…now it’s minutes” - DL, post launch
AI-powered summaries saved 2 hours per review and helped Kelly go into review discussions better prepared and less stressed. It also led to:

.svg)

